Мониторинг и анализ IT инфраструктуры
Заказчиком были озвучены следующие проблемы:
- Существующая служба технической поддержки ИТ инфраструктуры работает в режиме «после аварии», то есть исправляя аварийные ситуации. Как следствие – вынужденные простои большого количества сотрудников на время недоступности сервиса, высокие затраты на обеспечение требуемого SLA, сокрытие фактов предаварийного состояния критически важных объектов.
Цели проекта:
· Контроль и прозрачность соблюдения SLA· Сокращение затрат на поддержку
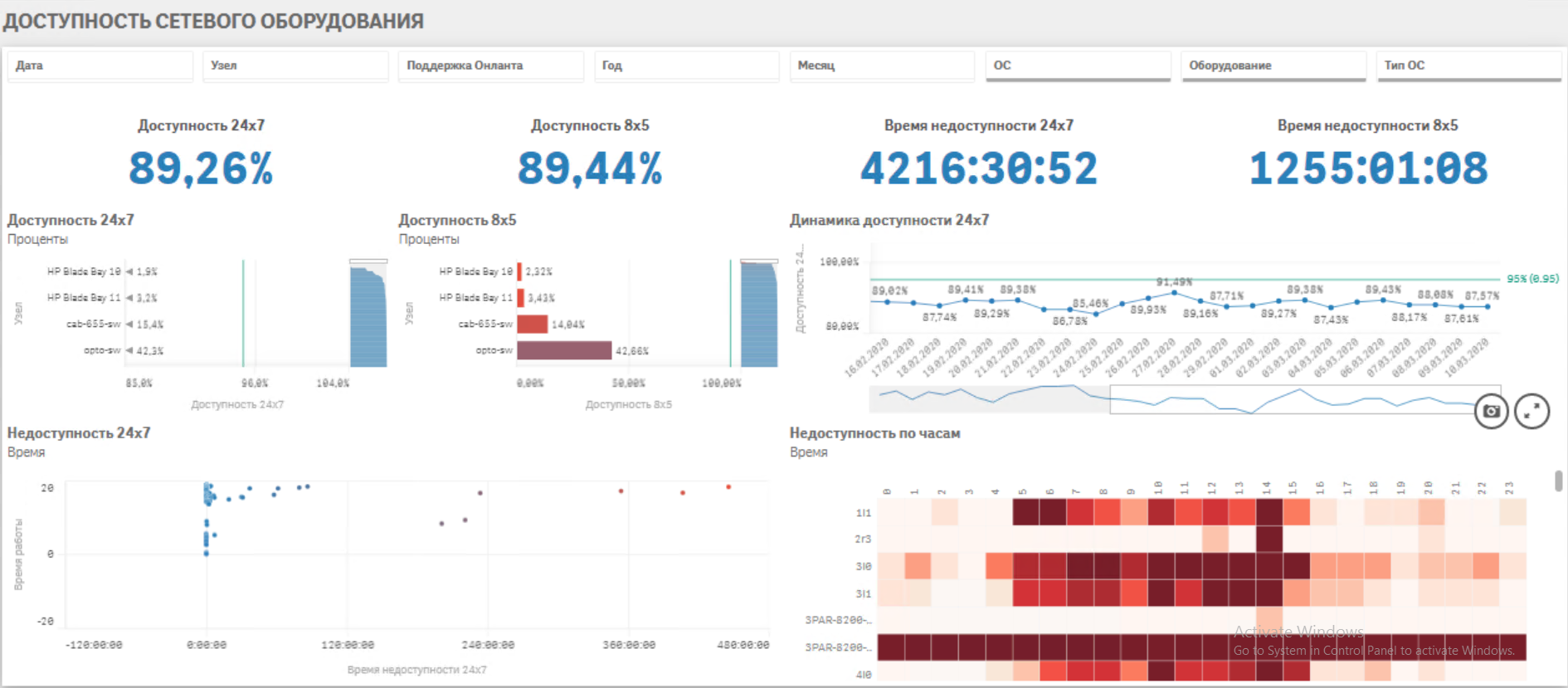
· Увеличение среднего показателя доступности оборудования и сервисов до 95% суммарного времени за счет своевременного предсказания аварийных ситуаций.
Задачи проекта:
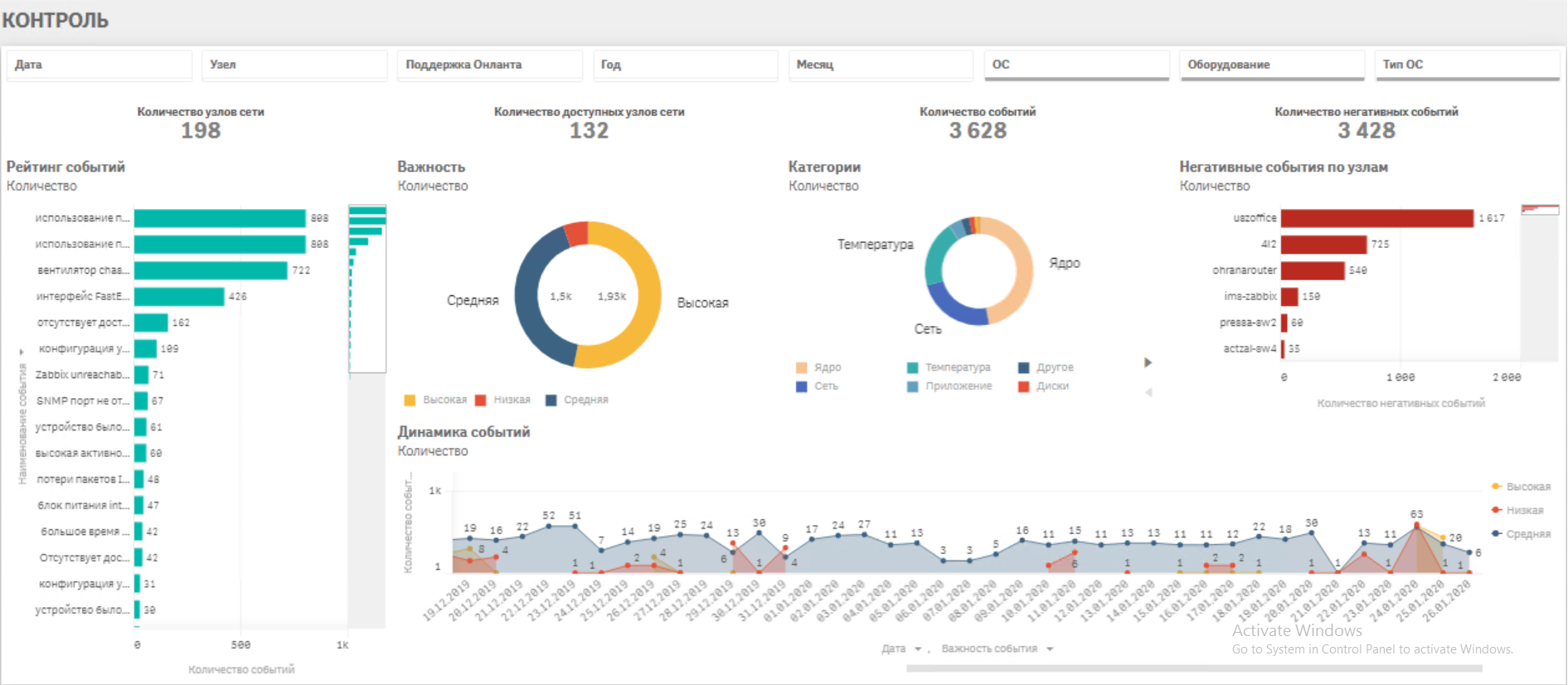
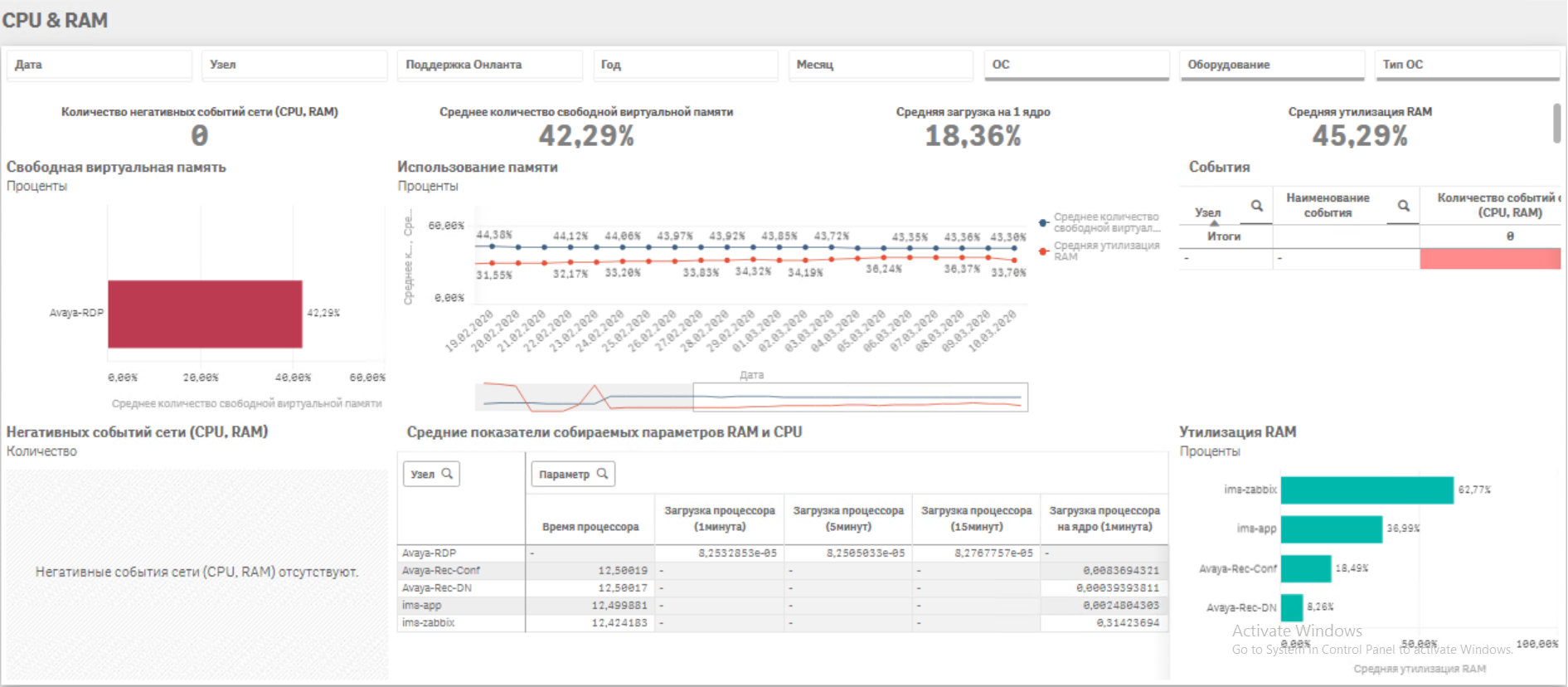
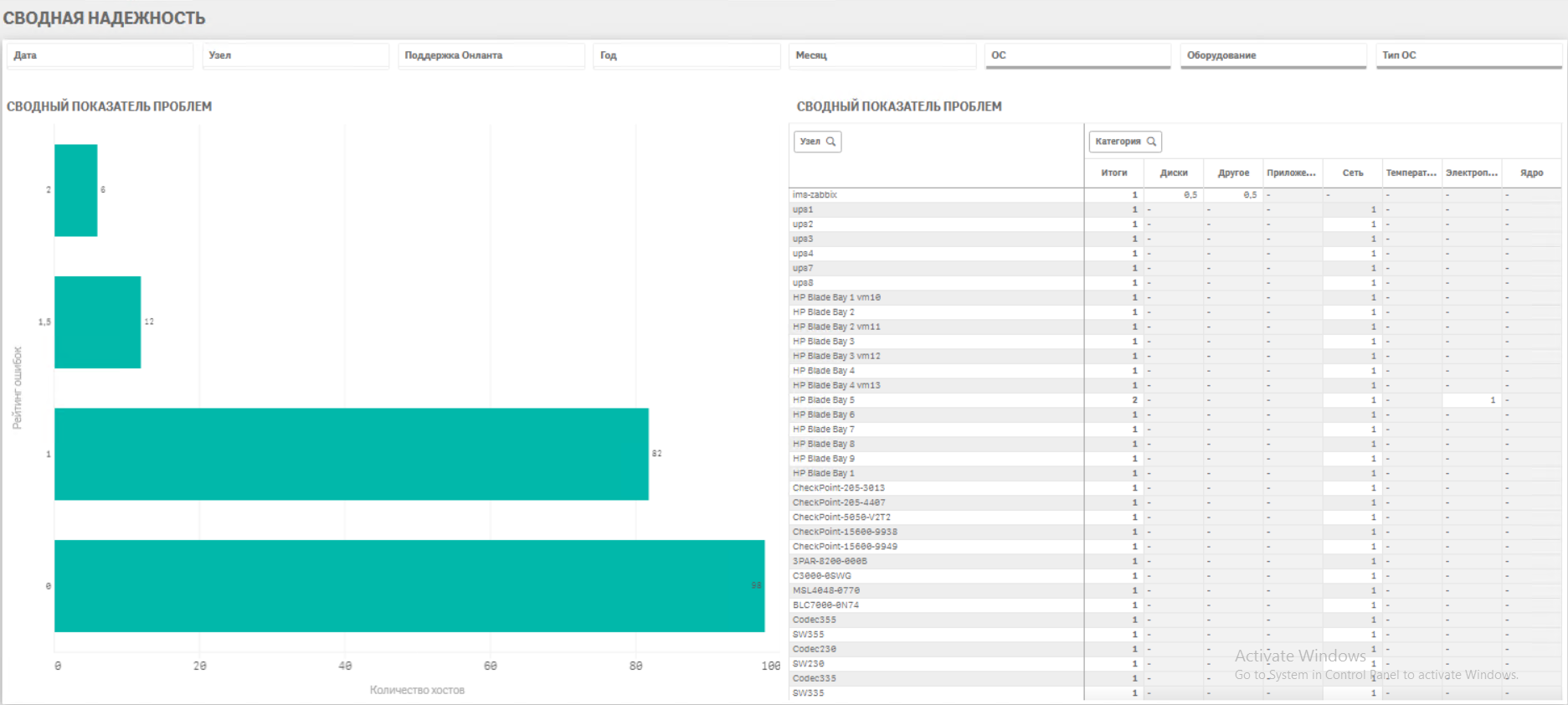
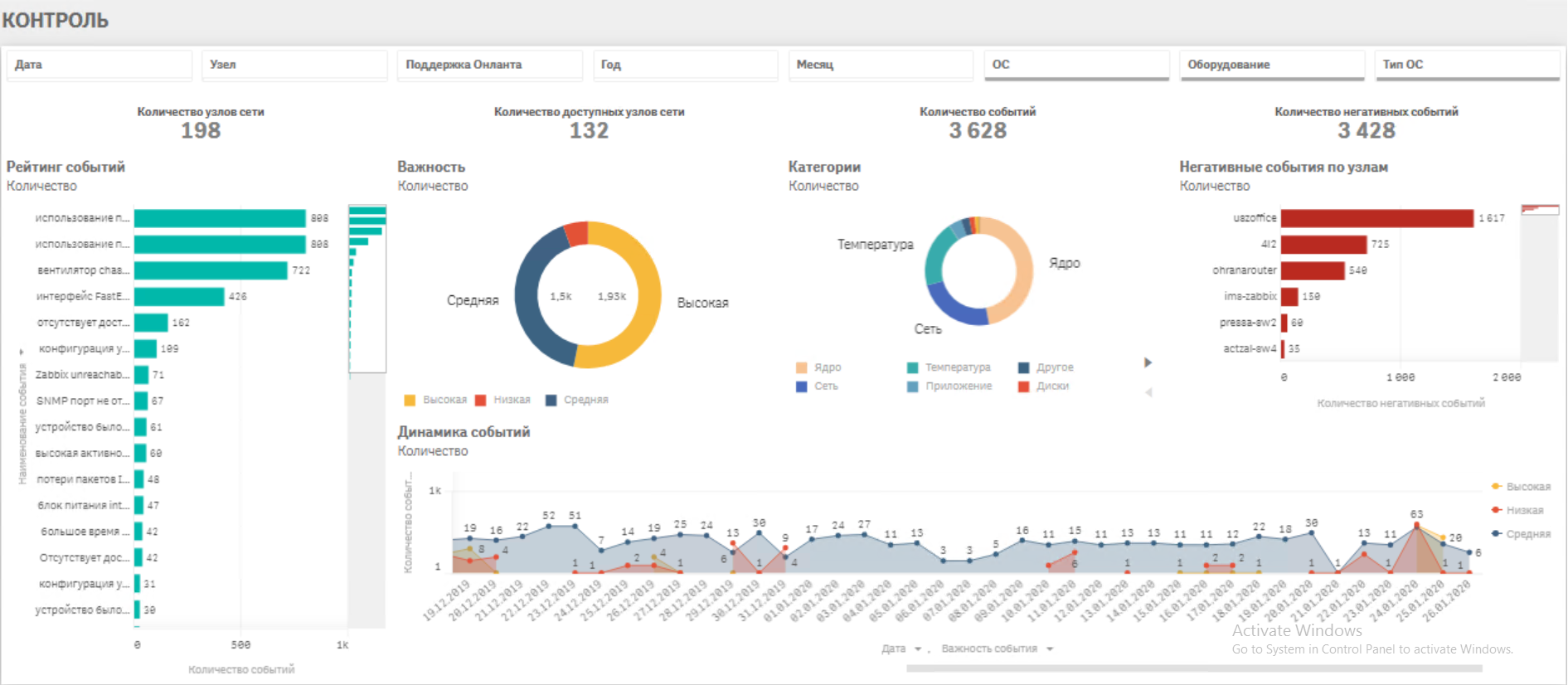
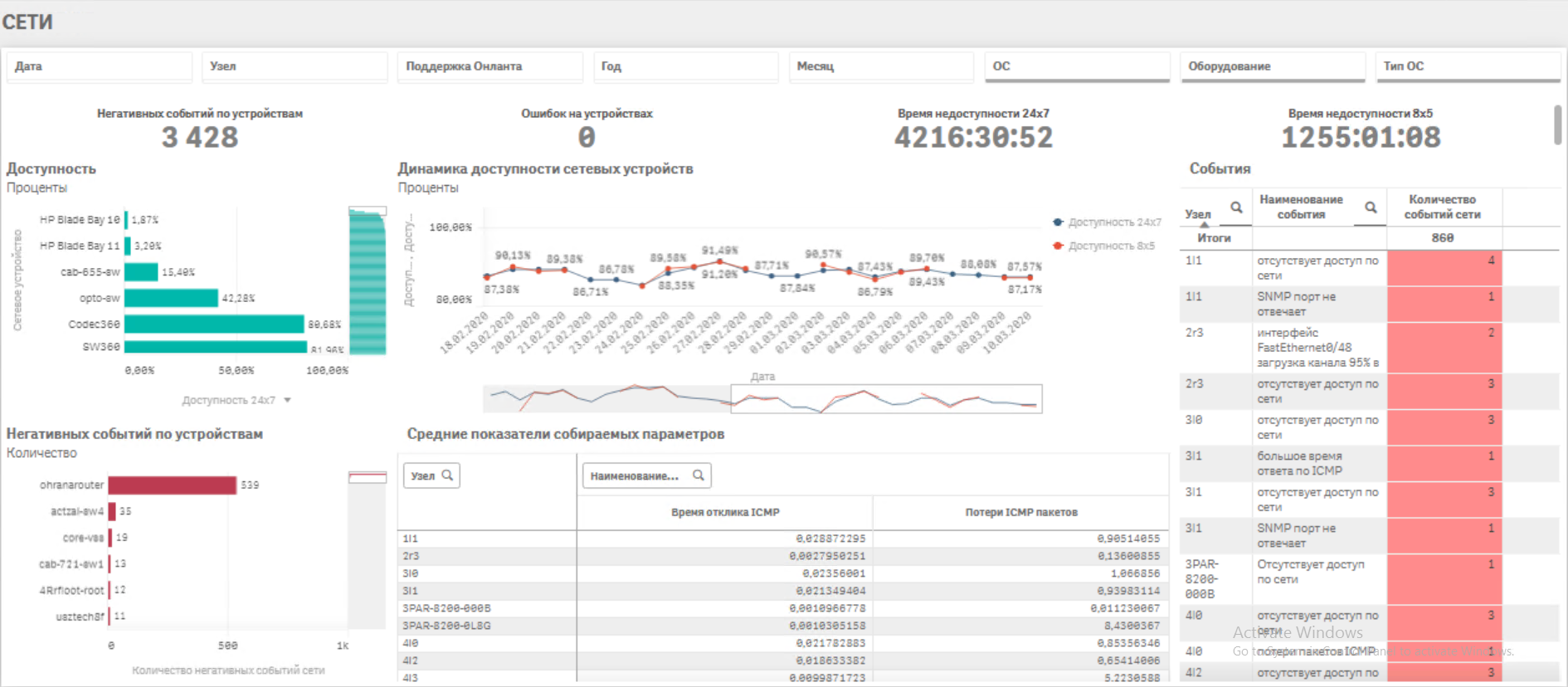
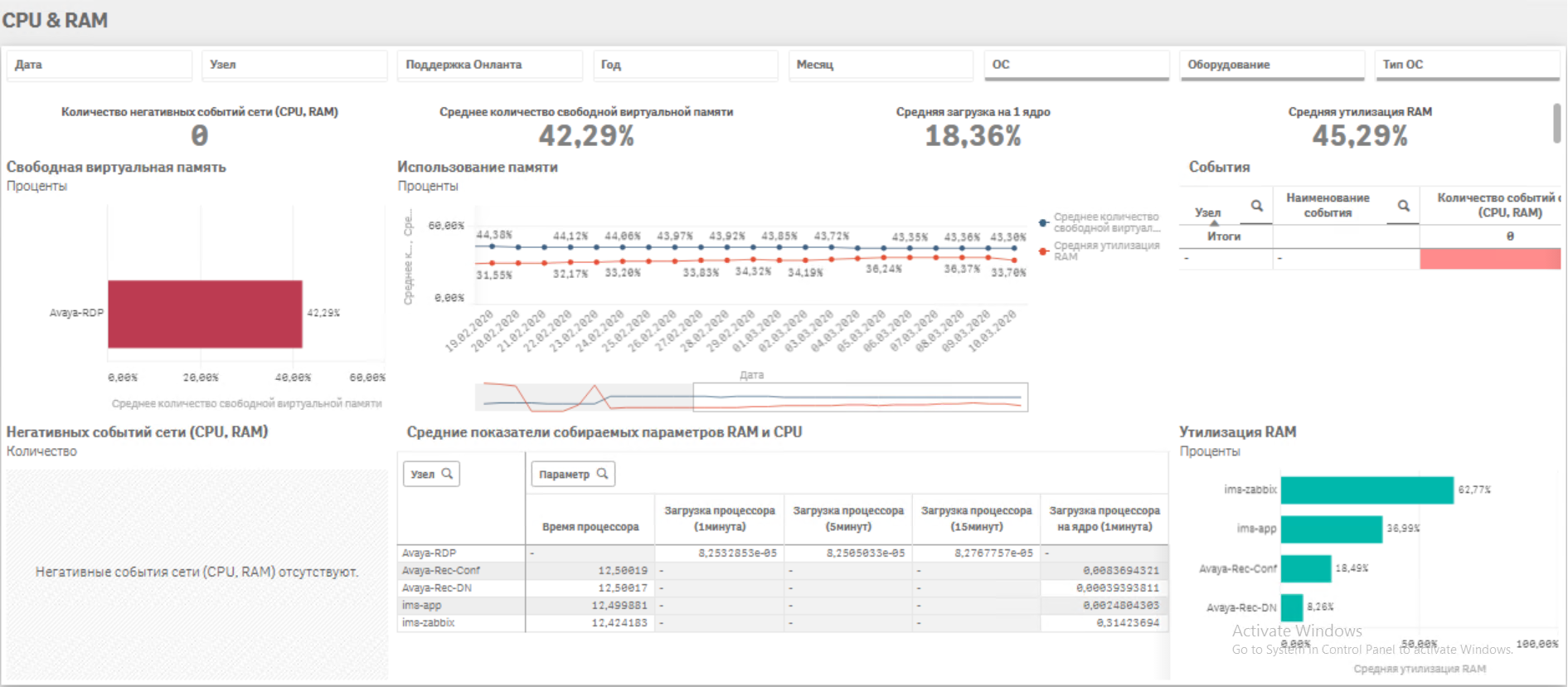
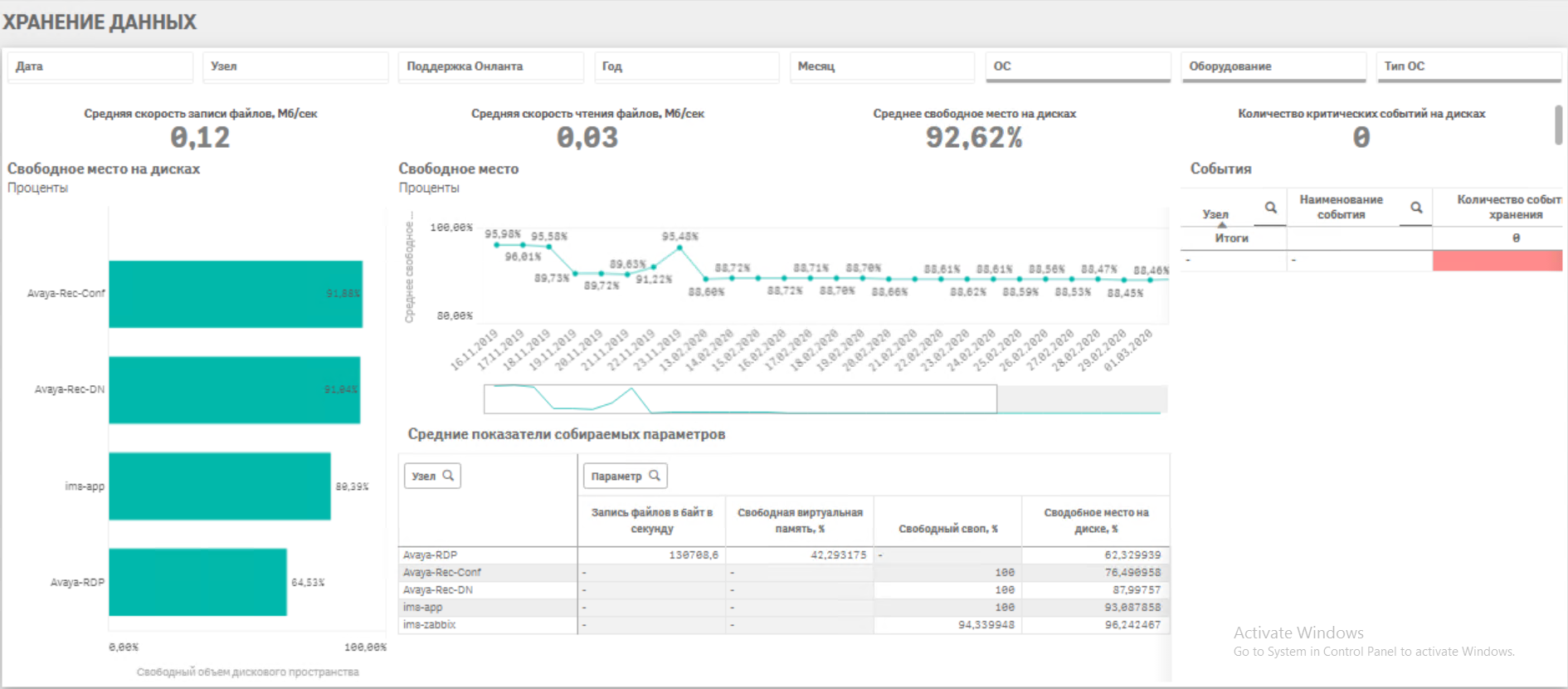
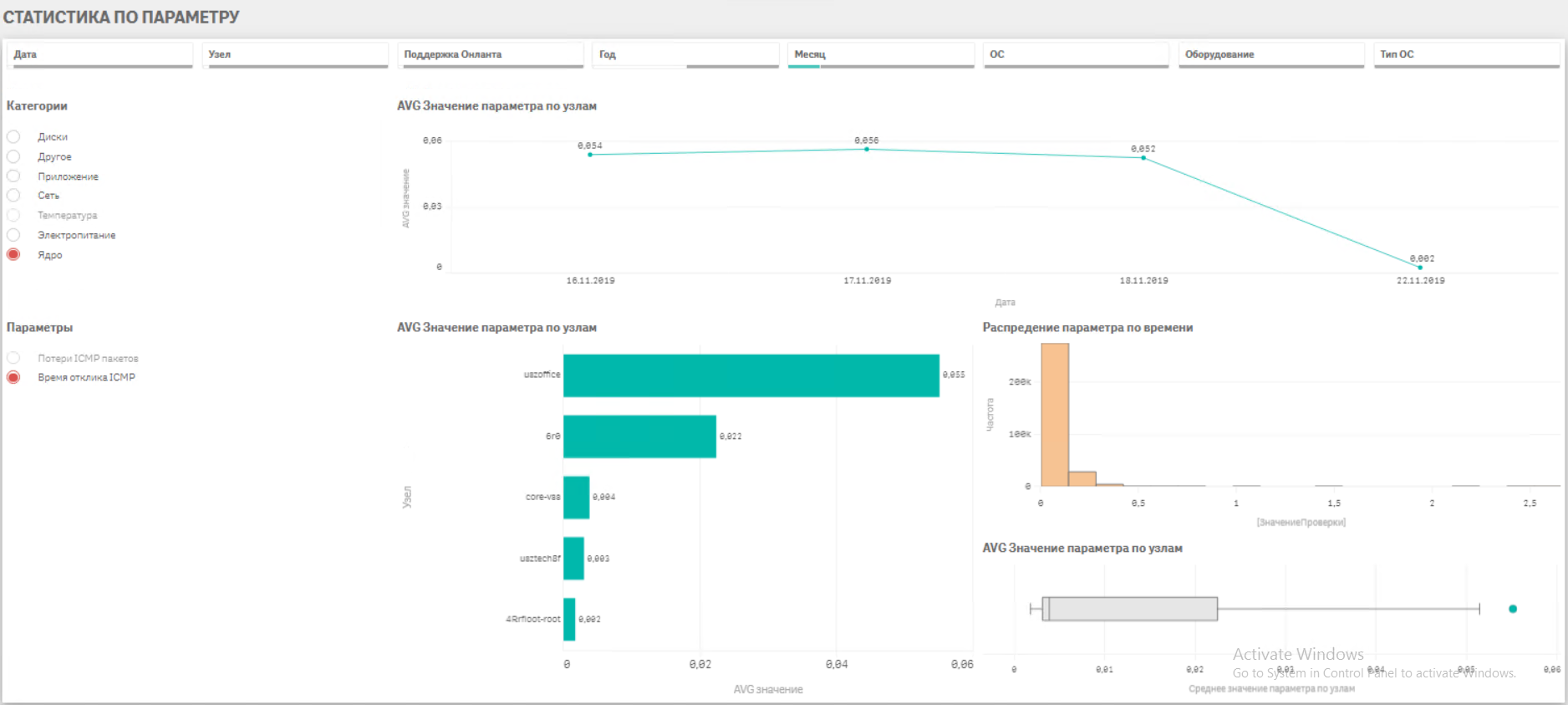
· Непрерывный мониторинг работоспособности всех объектов IT инфраструктуры· Сбор ретроспективных данных параметров оборудования в аналитическом хранилище
· Анализ данных и выявление связей факторов и событий, создающих аварийные ситуации
· Настройка уведомлений службы техподдержки о возникновении нежелательного тренда, вызывающего аварию (настройка триггеров)
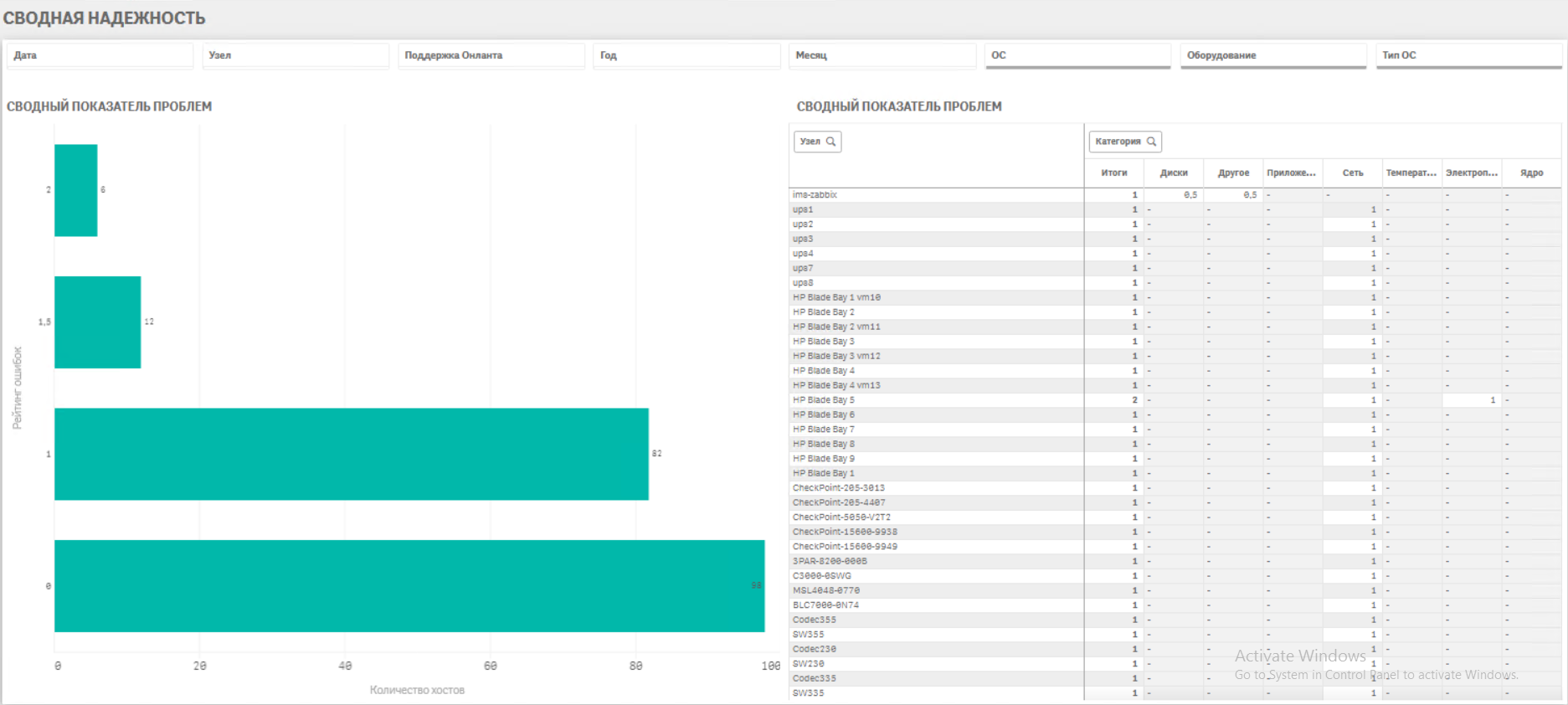
· Сбор аналитического отчета за период по наиболее критичным ситуациям, корректировка триггеров, подготовка итоговых отчетов на вышестоящий уровень.
Результаты проекта:
Используемые решения и технологии:
· Модуль мониторинга: Zabbix, Java, Glassfish, Postgresql, Grafana.
· Модуль аналитики: QlikSense, QlikNPrinting.
Продолжаем совместно с заказчиком успешно развивать еще один проект на базе решения - NMonitor Анализ мониторинга оборудования, сети передачи данных и сервисов
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}